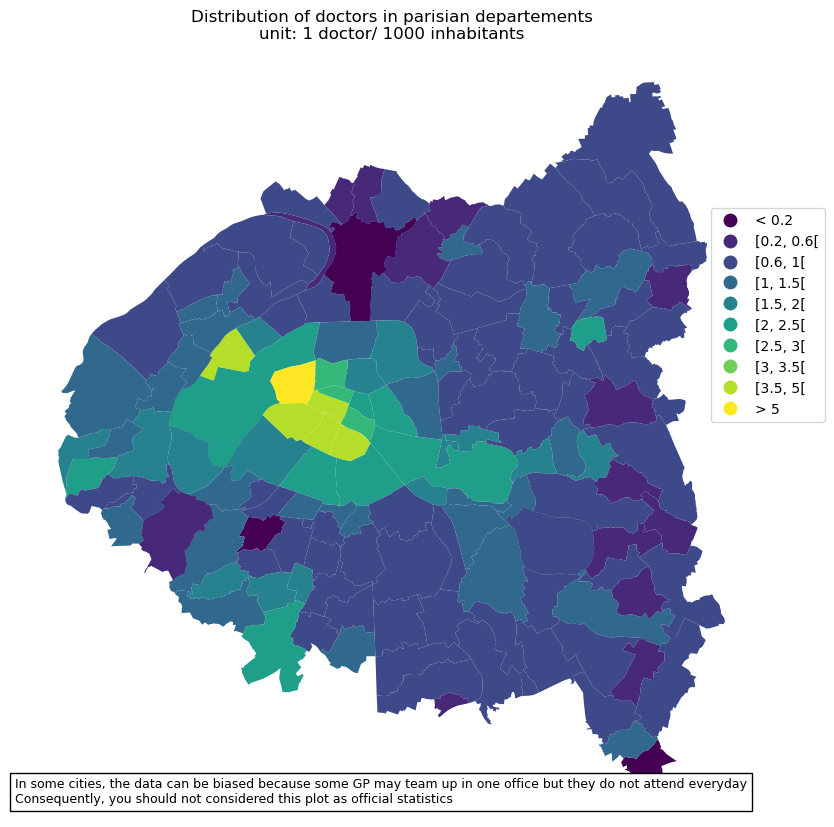
General Practitioners in parisian departements
[33]:
from pynsee.sirene import get_dimension_list, search_sirene
from pynsee.metadata import get_activity_list
from pynsee.geodata import get_geodata_list, get_geodata
from pynsee.localdata import get_geo_list
import difflib
import geopandas as gpd
import numpy
import pandas as pd
from pandas.api.types import CategoricalDtype
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import descartes
import re
from shapely.geometry import Polygon, MultiPolygon
from matplotlib.offsetbox import AnchoredText
[34]:
import logging
import sys
logging.basicConfig(stream=sys.stdout,
level=logging.INFO,
format="%(message)s")
[35]:
get_dimension_list().to_csv("sirene_dimensions.csv")
Previously saved data has been used:
/home/tfardet/.cache/pynsee/pynsee/3e054427d1b13bfc770c9c256b2dbe46.parquet
Creation date: 2025-02-07, today
Set update=True to get the most up-to-date data
[36]:
# get activity list
naf5 = get_activity_list('NAF5')
naf5.to_csv("naf.csv")
naf5[naf5["NAF5"].str.contains("^86.2")]
[36]:
| A10 | A129 | A17 | A21 | A38 | A5 | A64 | A88 | NAF1 | NAF2 | NAF3 | NAF4 | NAF5 | TITLE_NAF5_40CH_FR | TITLE_NAF5_65CH_FR | TITLE_NAF5_FR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 664 | OQ | Q86Z | OQ | Q | QA | OQ | QA0 | 86 | Q | 86 | 86.2 | 86.21 | 86.21Z | Activité des médecins généralistes | Activité des médecins généralistes | Activité des médecins généralistes |
| 665 | OQ | Q86Z | OQ | Q | QA | OQ | QA0 | 86 | Q | 86 | 86.2 | 86.22 | 86.22A | Act. radiodiagnostic et de radiothérapie | Activités de radiodiagnostic et de radiothérapie | Activités de radiodiagnostic et de radiothérapie |
| 666 | OQ | Q86Z | OQ | Q | QA | OQ | QA0 | 86 | Q | 86 | 86.2 | 86.22 | 86.22B | Activités chirurgicales | Activités chirurgicales | Activités chirurgicales |
| 667 | OQ | Q86Z | OQ | Q | QA | OQ | QA0 | 86 | Q | 86 | 86.2 | 86.22 | 86.22C | Autre activité des médecins spécialistes | Autres activités des médecins spécialistes | Autres activités des médecins spécialistes |
| 668 | OQ | Q86Z | OQ | Q | QA | OQ | QA0 | 86 | Q | 86 | 86.2 | 86.23 | 86.23Z | Pratique dentaire | Pratique dentaire | Pratique dentaire |
[37]:
# departements list of ile de france
list_dep = ["92", "93", "75", "94"] # + ["77", "78", "95", "91"]
string_dep = "|".join([dep + "*" for dep in list_dep])
string_dep
[37]:
'92*|93*|75*|94*'
[58]:
# search data on doctors
doctors = search_sirene(variable = ["activitePrincipaleEtablissement", "codePostalEtablissement"],
pattern = ['86.21Z*', string_dep],
number = 100000)
# '86.21Z' médecin généraliste
doctors = doctors[doctors["activitePrincipaleEtablissement"].str.contains("^86.21Z")].reset_index(drop=True)
Previously saved data has been used:
/home/tfardet/.cache/pynsee/pynsee/78cebe2f46279956f9948c8938f24c53.parquet
Creation date: 2025-02-07, today
Set update=True to get the most up-to-date data
[59]:
# filter
list_pattern = ["RADIOLOGIE", "IMAGERIE", "GYNECO", "DENTAIRE", "ANESTHES", 'P.M.I', 'INFANTILE', 'CARDIOLOG',
"MAXILLO", "HOSPITALIER", "OPHTALMO", "DERMATOLOG", 'PLANIFICATION', 'MAIRIE', 'THORACIQUE',
"TOMODENSITOM", "URGENCE", "NEPHROLOG", "PRAXEA", 'VACCINATION', 'SCOLAIRE', 'CANCER', 'STOMATOLO',
"URODYNAMIQ", "CARDIORIS", "CHIRPLASTIQUE", "NINAMAX", "CICOF", 'MATERNELLE', 'DIALYSE',
'RADIOTHERAPIE', 'RHUMATOLOG', 'DENTISTE', 'ECHOGRAPH', 'PATHOLOG', 'CHIRURGIE', 'ESTHETIQ',
'CYTOLOG', 'ORTHOPED']
pattern = r"|".join(list_pattern)
[60]:
# clean up the data not related to general practitioners but to other health activities
doctors = doctors[~doctors["denominationUniteLegale"].str.contains(pattern, regex=True, na=False)].reset_index(drop=True)
doctors = doctors[~doctors["enseigne1Etablissement"].str.contains(pattern, regex=True, na=False)].reset_index(drop=True)
# exclude association and administration
doctors = doctors[~doctors["categorieJuridiqueUniteLegale"].isin(["9220", "7220"])].reset_index(drop=True)
doctors = doctors.sort_values(["categorieJuridiqueUniteLegale"])
doctors.to_csv("doctors.csv")
list_denomination_uniteLegale = doctors.denominationUniteLegale.unique()
[ ]:
# get geographical data list
geodata_list = get_geodata_list()
# get communes geographical limits
com = get_geodata('ADMINEXPRESS-COG-CARTO.LATEST:commune')
# get arrondissement (subdivision of departement) geographical limits
arr = get_geodata('ADMINEXPRESS-COG-CARTO.LATEST:arrondissement')
Previously saved data has been used:
/home/tfardet/.cache/pynsee/pynsee/e879822687bab4b12f23762b5d56742b.parquet
Creation date: 2025-02-07, today
Set update=True to get the most up-to-date data
[42]:
# get arrondissement municipal geographical limits
arrmun = get_geodata('ADMINEXPRESS-COG-CARTO.LATEST:arrondissement_municipal')
arrmun = arrmun[arrmun.insee_com.str.contains('^75')].reset_index(drop=True)
arrmun["nom_m"] = arrmun["nom_m"].apply(lambda x: re.sub(r"ER|E", "", re.sub(" ARRONDISSEMENT", "", x)))
arrmun = arrmun.rename(columns={"geometry" : "geometry2",
"population" : "population2",
"nom_m" : "nom_m2"})
arrmun = arrmun[["nom_m2", "geometry2", "population2"]]
Previously saved data has been used:
/home/tfardet/.cache/pynsee/pynsee/25e148c283d20f478d44c0ed19a75b73.parquet
Creation date: 2025-02-07, today
Set update=True to get the most up-to-date data
[43]:
def _replace_nan(x, y):
if (x is None) or (numpy.isnan(x)):
return y
else:
return x
[44]:
doctors
[44]:
| siren | nic | siret | dateDebut | dateCreationEtablissement | dateCreationUniteLegale | dateFin | denominationUniteLegale | nomUniteLegale | prenomUsuelUniteLegale | ... | codePostal2Etablissement | libelleCommune2Etablissement | libelleCommuneEtranger2Etablissement | distributionSpeciale2Etablissement | codeCommune2Etablissement | codeCedex2Etablissement | libelleCedex2Etablissement | codePaysEtranger2Etablissement | libellePaysEtranger2Etablissement | enseigne3Etablissement | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9754 | 934302480 | 00017 | 93430248000017 | 2024-11-01 | 2024-11-01 | 2024-11-01 | None | None | MAKNI | SAMIA | ... | None | None | None | None | None | None | None | None | None | None |
| 5509 | 494498017 | 00040 | 49449801700040 | 2021-01-04 | 2021-01-04 | 2006-01-17 | None | None | HERAULT | NATHALIE | ... | None | None | None | None | None | None | None | None | None | None |
| 5508 | 494422066 | 00030 | 49442206600030 | 2014-07-07 | 2014-07-07 | 2006-06-09 | None | None | VENTRE | MARIE | ... | None | None | None | None | None | None | None | None | None | None |
| 5507 | 494390701 | 00022 | 49439070100022 | 2015-04-01 | 2015-04-01 | 2007-01-01 | None | None | KARRAZ | WAEL | ... | None | None | None | None | None | None | None | None | None | None |
| 5506 | 494260391 | 00045 | 49426039100045 | 2019-11-28 | 2019-11-28 | 2006-11-09 | None | None | BOTHNER | LAURENT | ... | None | None | None | None | None | None | None | None | None | None |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6262 | 775665805 | 00468 | 77566580500468 | 2008-01-01 | 1996-12-25 | 1900-01-01 | None | COMPAGNIE FILLES CHARITE ST VINCENT PAUL | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 6274 | 775683006 | 00362 | 77568300600362 | 2017-06-21 | 2017-06-21 | 1900-01-01 | None | FONDATION SANTE DES ETUDIANTS DE FRANCE | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 6261 | 775663883 | 00020 | 77566388300020 | 2008-01-01 | 1900-01-01 | 1900-01-01 | None | INSTITUT ARTHUR VERNES | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 268 | 313711038 | 00015 | 31371103800015 | 2008-01-01 | 1978-01-01 | 1978-01-01 | None | FONDATION HAHNEMANN | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 206 | 310227749 | 00010 | 31022774900010 | 2008-01-01 | 1900-01-01 | 1900-01-01 | None | CENTRE DE SOINS | None | None | ... | None | None | None | None | None | None | None | None | None | None |
10043 rows × 96 columns
[45]:
# count general practioners by commun
hdLegalStatus = doctors.groupby(['categorieJuridiqueUniteLegale'], dropna=True)['effectifsMinEtablissement'].agg(['mean', "count"])
hdLegalStatus["meanHeadcountLegalStatus"] = hdLegalStatus["mean"].apply(lambda x: _replace_nan(x, 1))
hdLegalStatus["categorieJuridiqueUniteLegale"] = hdLegalStatus.index
hdLegalStatus.loc[hdLegalStatus["categorieJuridiqueUniteLegale"] == "1000", "meanHeadcountLegalStatus"] = 1
hdLegalStatus = hdLegalStatus.reset_index(drop=True)
doctors = doctors.merge(hdLegalStatus, how = "left", on = "categorieJuridiqueUniteLegale").reset_index(drop=True)
for r in doctors.index:
hdMin = doctors.loc[r, "effectifsMinEtablissement"]
if (hdMin is None) or (numpy.isnan(hdMin)):
doctors.loc[r, "headcount"] = doctors.loc[r, "meanHeadcountLegalStatus"]
else:
doctors.loc[r, "headcount"] = hdMin
[46]:
# duplicates cleaning
# normalization to avoid double counting
doctors["headcountFinal"] = doctors["headcount"] / doctors.groupby("siren", dropna=True)["headcount"].transform("sum")
#visual check duplicates
dupDoctors = doctors[doctors["siren"].duplicated(keep=False)].reset_index(drop=True)
dupDoctors.to_csv("dupDoctors.csv")
list_adress_var = ["numeroVoieEtablissement", "typeVoieEtablissementLibelle",
"libelleVoieEtablissement", "codePostalEtablissement", "libelleCommuneEtablissement"]
addressDupDoctors = doctors[doctors[list_adress_var].duplicated(keep=False)].reset_index(drop=True)
addressDupDoctors = addressDupDoctors.sort_values(list_adress_var)
addressDupDoctors.to_csv("addressDupDoctors.csv")
[47]:
doctors.sort_values(["libelleCommuneEtablissement"]).to_csv("doctorSortedCom.csv")
[48]:
# count general practioners by commune
doctorsCom = doctors.groupby(['libelleCommuneEtablissement', 'codePostalEtablissement'])['headcountFinal'].agg(['sum'])
doctorsCom = doctorsCom.rename(columns = {"sum" : "headcount"})
doctorsCom
[48]:
| headcount | ||
|---|---|---|
| libelleCommuneEtablissement | codePostalEtablissement | |
| ABLON-SUR-SEINE | 94480 | 2.000000 |
| ALFORTVILLE | 94140 | 29.250000 |
| ANTONY | 92160 | 131.406046 |
| ARCUEIL | 94110 | 14.500000 |
| ASNIERES-SUR-SEINE | 92600 | 67.629197 |
| ... | ... | ... |
| VILLETANEUSE | 93430 | 5.000000 |
| VILLIERS SUR MARNE | 94350 | 1.000000 |
| VILLIERS-SUR-MARNE | 94350 | 13.250000 |
| VINCENNES | 94300 | 70.640814 |
| VITRY-SUR-SEINE | 94400 | 79.257402 |
189 rows × 1 columns
[49]:
doctorsCom["libelleCommuneEtablissement"] = doctorsCom.index.get_level_values("libelleCommuneEtablissement")
doctorsCom["codePostalEtablissement"] = doctorsCom.index.get_level_values("codePostalEtablissement")
doctorsCom = doctorsCom.reset_index(drop=True)
[50]:
import os, sys
communes = get_geo_list("communes")
def _find_commune_identifier(com, dep, communes=communes):
try:
list_com = [c.upper() for c in communes.TITLE.to_list()]
communes["TITLE"] = list_com
communes = communes[communes["CODE_DEP"] == dep].reset_index(drop=True)
match = difflib.get_close_matches(com.upper(), list_com)[0]
cog = communes[communes["TITLE"] == match].reset_index(drop=True)
cog = cog.loc[0, "CODE"]
except:
cog = None
return cog
for r in doctorsCom.index:
dep = doctorsCom.loc[r, "codePostalEtablissement"][:2]
comName = doctorsCom.loc[r, "libelleCommuneEtablissement"]
doctorsCom.loc[r, "insee_com"] = _find_commune_identifier(comName, dep)
Previously saved data has been used:
/home/tfardet/.cache/pynsee/pynsee/9807b8fe5399f855c1c5cf4d46ae21a7.parquet
Creation date: 2025-02-07, today
Set update=True to get the most up-to-date data
[51]:
comDep = com[com["insee_dep" ].isin(list_dep)].reset_index(drop=True)
doctorsCom2 = comDep.merge(doctorsCom, how = "left", on = "insee_com")
[52]:
doctorsCom2["headcount"] = doctorsCom2["headcount"].apply(lambda x: _replace_nan(x, 0))
[53]:
doctorsCom2["headcount"] = doctorsCom2["headcount"].apply(lambda x: _replace_nan(x, 0))
doctorsCom2["ratio"] = 1000 * doctorsCom2["headcount"] / doctorsCom2["population"]
[54]:
doctorsCom2 = doctorsCom2.reset_index(drop=True)
doctorsCom4 = doctorsCom2[doctorsCom2.columns].merge(arrmun, left_on ="libelleCommuneEtablissement", right_on="nom_m2", how="left")
for i in doctorsCom4.index:
if type(doctorsCom4.loc[i, 'geometry2']) in [MultiPolygon, Polygon]:
doctorsCom4.loc[i, 'geometry'] = doctorsCom4.loc[i, 'geometry2']
doctorsCom4.loc[i, "ratio"] = 1000 * doctorsCom4.loc[i,"headcount"] / doctorsCom4.loc[i,"population2"]
del doctorsCom4["geometry2"]
doctorsCom2Map = gpd.GeoDataFrame(doctorsCom4)
[55]:
doctorsCom2Map = gpd.GeoDataFrame(doctorsCom4)
[56]:
# compute density ranges of GP
doctorsCom2Map.loc[doctorsCom2Map.ratio < 1, 'range'] = "< 0.2"
doctorsCom2Map.loc[doctorsCom2Map.ratio >= 5, 'range'] = "> 5"
density_ranges = [0.2, 0.6, 1, 1.5, 2, 2.5, 3, 3.5, 5]
list_ranges = []
list_ranges.append( "< 0.2")
for i in range(len(density_ranges)-1):
min_range = density_ranges[i]
max_range = density_ranges[i+1]
range_string = "[{}, {}[".format(min_range, max_range)
rows = (doctorsCom2Map.ratio >= min_range) & (doctorsCom2Map.ratio < max_range)
doctorsCom2Map.loc[rows, 'range'] = range_string
list_ranges.append(range_string)
list_ranges.append("> 5")
doctorsCom2Map['range2'] = doctorsCom2Map['range'].astype(CategoricalDtype(categories=list_ranges, ordered=True))
[26]:
# make plot
txt = 'In some cities, the data can be biased because some GP may team up in one office but they do not attend everyday'
txt += '\nConsequently, you should not considered this plot as official statistics'
fig, ax = plt.subplots(1,1,figsize=[10,10])
doctorsCom2Map.plot(column='range2', cmap=cm.viridis,
legend=True, ax=ax,
legend_kwds={'bbox_to_anchor': (1.1, 0.8)})
ax.set_axis_off()
ax.set(title='Distribution of doctors in parisian departements\nunit: 1 doctor/ 1000 inhabitants')
at = AnchoredText(txt, prop=dict(size=9), frameon=True, loc=4)
ax.add_artist(at)
plt.show()
[ ]: